indexing in Databases
- Indexing is a way to optimize the performance of a database by minimizing the disk accesses required when a query is processed.
- It is a data structure technique which is used to quickly locate and access the data in a database.
- Indexes are created using a few database columns.
- The first column is the Search key that contains a copy of the primary key or candidate key of the table. These values are stored in sorted order so that the corresponding data can be accessed quickly.
- Note: The data may or may not be stored in sorted order.
- The second column is the Data Reference or Pointer which contains a set of pointers holding the address of the disk block where that particular key value can be found.
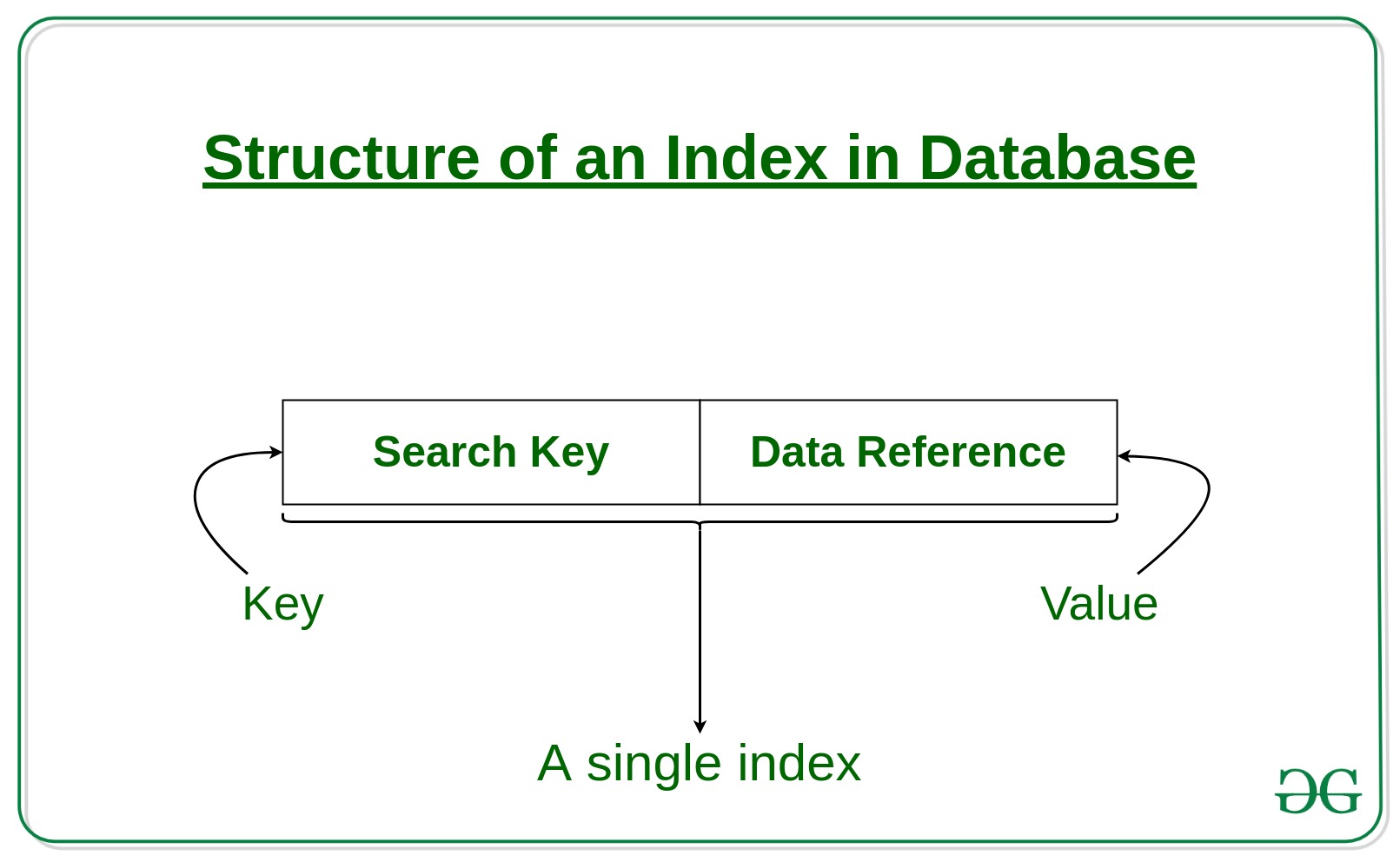
- The indexing has various attributes:
- Access Types: This refers to the type of access such as value based search, range access, etc.
- Access Time: It refers to the time needed to find particular data element or set of elements.
- Insertion Time: It refers to the time taken to find the appropriate space and insert a new data.
- Deletion Time: Time taken to find an item and delete it as well as update the index structure.
- Space Overhead: It refers to the additional space required by the index.
- In general, there are two types of file organization mechanism which are followed by the indexing methods to store the data:
- Sequential File Organization or Ordered Index File
- Dense Index
- Sparse Index
- Hash File organization
- Clustered Indexing
- Non-Clustered or Secondary Indexing
- Multilevel Indexing
- Sequential File Organization or Ordered Index File
Sequential File Organization or Ordered Index File
In this, the indices are based on a sorted ordering of the values. These are generally fast and a more traditional type of storing mechanism. These Ordered or Sequential file organization might store the data in a dense or sparse format:
- Dense Index:
For every search key value in the data file, there is an index record. This record contains the search key and also a reference to the first data record with that search key value.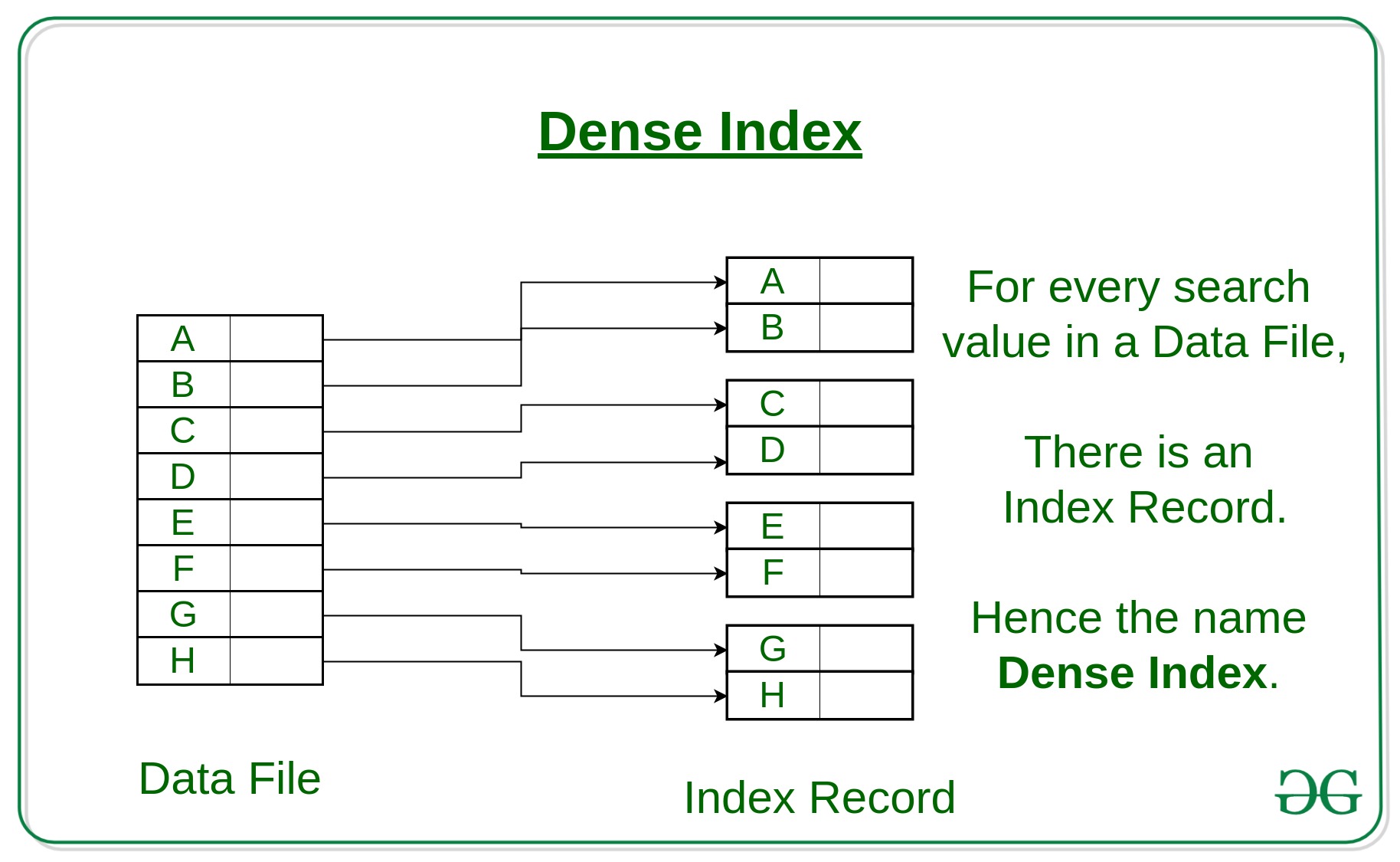
and dense Index means data is ordered or listed in one place near each other
- Sparse Index:
The index record appears only for a few items in the data file. Each item points to a block as shown. To locate a record, we find the index record with the largest search key value less than or equal to the search key value we are looking for. We start at that record pointed to by the index record, and proceed along with the pointers in the file (that is, sequentially) until we find the desired record.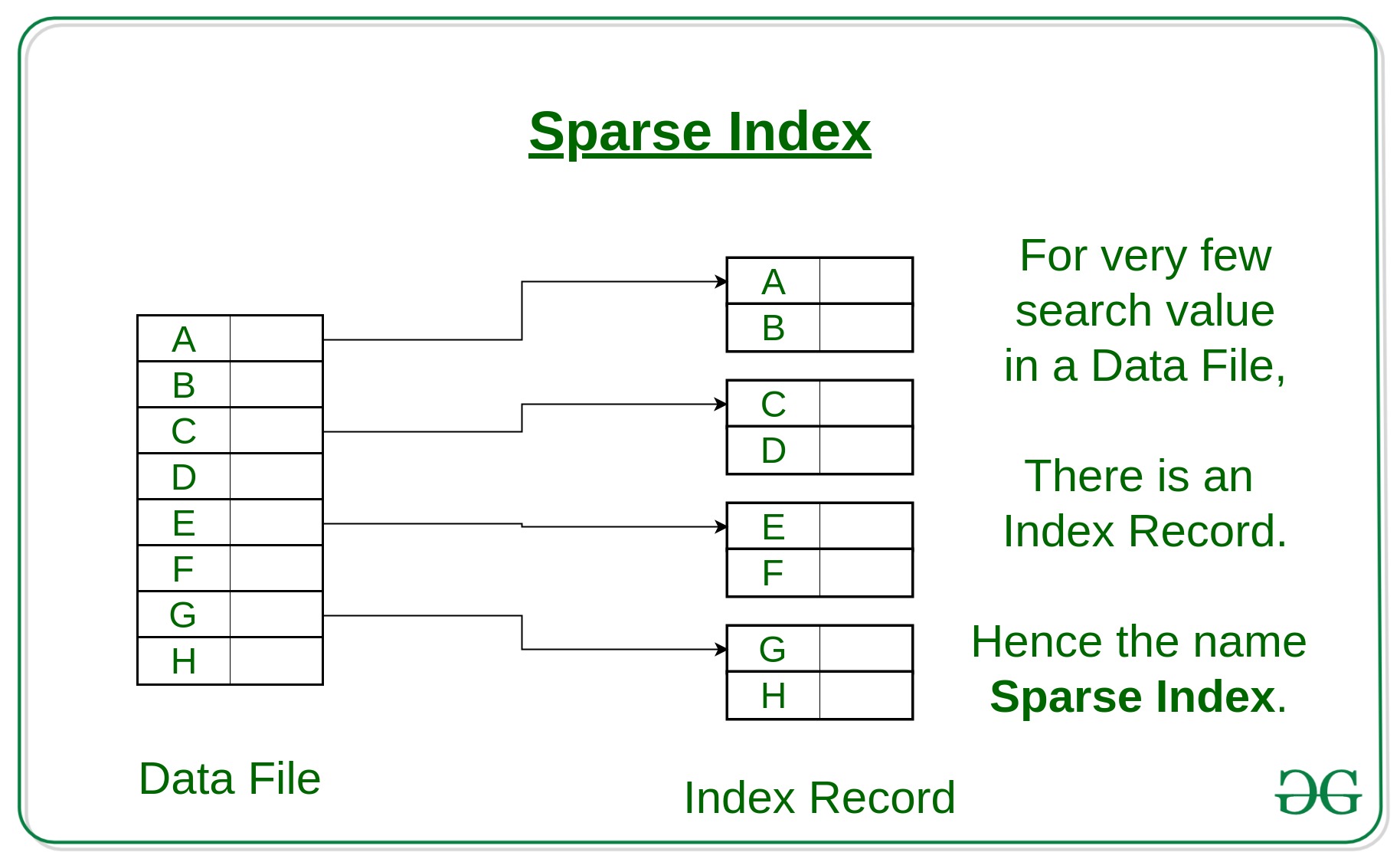 and sparse index means data indices are saved with concept of pages or trees where data is fetched with its page index not with its index pointer location
,thus we can conclude that dense index pointer directly points to data while sparse index directly points to an object,page or tree that contains a list of pointers that points to our data
and sparse index means data indices are saved with concept of pages or trees where data is fetched with its page index not with its index pointer location
,thus we can conclude that dense index pointer directly points to data while sparse index directly points to an object,page or tree that contains a list of pointers that points to our data
Hash File organization
Indices are based on the values being distributed uniformly across a range of buckets. The buckets to which a value is assigned is determined by a function called a hash function.
There are primarily three methods of indexing:
- Clustered Indexing
- Non-Clustered or Secondary Indexing
- Multilevel Indexing
- Unique and non-unique indexes
- Bidirectional indexes
Clustered Indexing
When more than two records are stored in the same file these types of storing known as cluster indexing. By using the cluster indexing we can reduce the cost of searching reason being multiple records related to the same thing are stored at one place and it also gives the frequent joining of more than two tables (records). Clustering index is defined on an ordered data file. The data file is ordered on a non-key field. In some cases, the index is created on non-primary key columns which may not be unique for each record. In such cases, in order to identify the records faster, we will group two or more columns together to get the unique values and create index out of them. This method is known as the clustering index. Basically, records with similar characteristics are grouped together and indexes are created for these groups. For example, students studying in each semester are grouped together. i.e. 1st Semester students, 2nd semester students, 3rd semester students etc. are grouped.
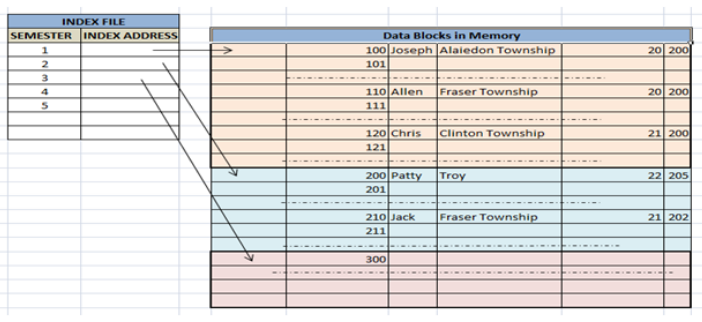
this type of indexes involves
- order data according to the indexed column or can be performed over ordered data
- then group all columns with the same characteristics such as if we are indexing a semester column in a table then order students accordingly to each semester then group each semester students
- then take the first record pointer and save it in an index file in order to make its fetch process more fast
- so we can conclude that clustered indexes contains the addresses of each group first pointer not the data itself in order to increase access speed
- also Clustered indexes are indexes whose order of the rows in the data pages corresponds to the order of the rows in the index. This order is why only one clustered index can exist in any table, whereas, many non-clustered indexes can exist in the table. In some database systems, the leaf node of the clustered index corresponds to the actual data, not a pointer to data that is found elsewhere.
Non-Clustered or Secondary Indexing
A non clustered index just tells us where the data lies, i.e. it gives us a list of virtual pointers or references to the location where the data is actually stored. Data is not physically stored in the order of the index. Instead, data is present in leaf nodes. For e.g. the contents page of a book. Each entry gives us the page number or location of the information stored. The actual data here(information on each page of the book) is not organized but we have an ordered reference(contents page) to where the data points actually lie. We can have only dense ordering in the non-clustered index as sparse ordering is not possible because data is not physically organized accordingly. It requires more time as compared to the clustered index because some amount of extra work is done in order to extract the data by further following the pointer. In the case of a clustered index, data is directly present in front of the index.
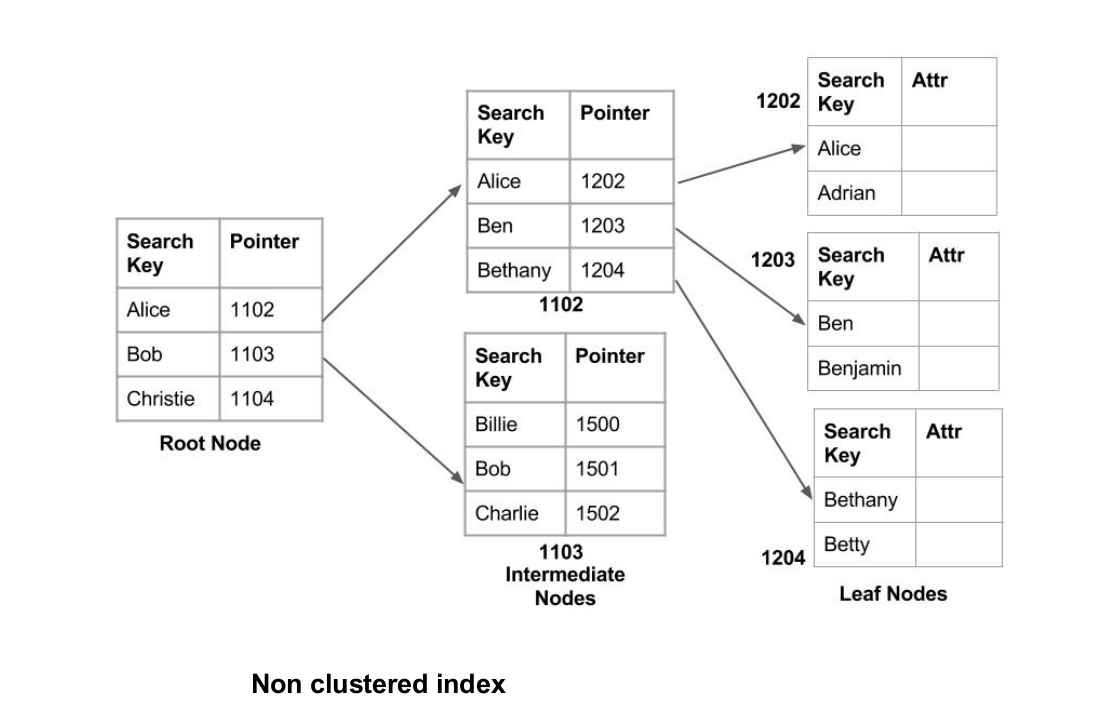
this non-clustered index involved
- creating a list of ordered pointer in memory and put ordered data accordingly in each reference
- then we would have a list of pointers equals to the list of records in our document or table
- but indexes are not in the same order of records in our table
- so non-clustered indexes are dense in it’s structure
- and a clustered indexes are sparse indexes in its structure because it is ordered and grouped with each group reference in an index file
Multilevel Indexing
With the growth of the size of the database, indices also grow. As the index is stored in the main memory, a single-level index might become too large a size to store with multiple disk accesses. The multilevel indexing segregates the main block into various smaller blocks so that the same can stored in a single block. The outer blocks are divided into inner blocks which in turn are pointed to the data blocks. This can be easily stored in the main memory with fewer overheads.
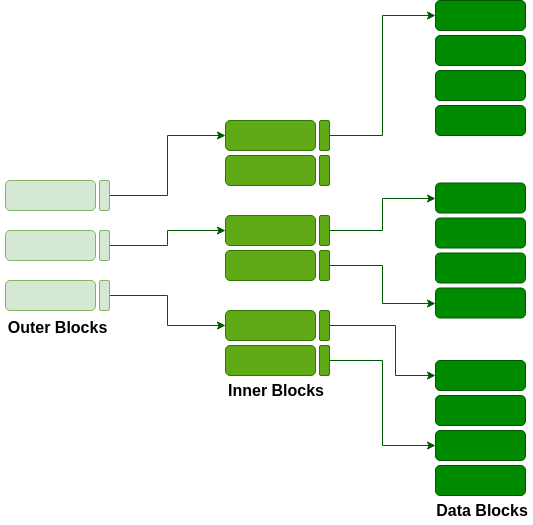
this process involves dividing the main index file into smaller indices in order to reduce the memory overhead by nesting pointers accordingly to keep index access speed with lower memory overhead
Unique and non-unique indexes
Unique indexes are indexes that help maintain data integrity by ensuring that no two rows of data in a table have identical key values. When you create a unique index for an existing table with data, values in the columns or expressions that comprise the index key are checked for uniqueness. If the table contains rows with duplicate key values, the index creation process fails. When a unique index is defined for a table, uniqueness is enforced whenever keys are added or changed within the index. This enforcement includes insert, update, load, import, and set integrity, to name a few. In addition to enforcing the uniqueness of data values, a unique index can also be used to improve data retrieval performance during query processing.
Non-unique indexes are not used to enforce constraints on the tables with which they are associated. Instead, non-unique indexes are used solely to improve query performance by maintaining a sorted order of data values that are used frequently.
Including and excluding NULL keys
Unique and non-unique indexes can be created so that a key is not inserted into the index object when all columns or expressions of the key are null. Excluding null keys can result in improved storage and performance optimization for cases where you do not want queries to access data associated with null keys. For unique indexes, the enforcement of the uniqueness of table data ignores rows where the index key is null.
Differences between primary key or unique key constraints and unique indexes
It is important to understand that there is no significant difference between a primary key or unique key constraint and a unique index. To implement the concept of primary and unique key constraints, the database manager uses a combination of a unique index and the NOT NULL constraint. Therefore, unique indexes do not enforce primary key constraints by themselves because they allow null values. Although null values represent unknown values, when it comes to indexing, a null value is treated as being equal to other null values.
Therefore, if a unique index consists of a single column, only one null value is allowed-more than one null value would violate the unique constraint. Similarly, if a unique index consists of multiple columns, a specific combination of values and nulls can be used only one time.
Both clustered and non-clustered indexes contain only keys and record identifiers in the index structure. The record identifiers always point to rows in the data pages. With clustered indexes, the database manager attempts to keep the data in the data pages in the same order as the corresponding keys in the index pages. Thus the database manager attempts to insert rows with similar keys onto the same pages. If the table is reorganized, data is inserted into the data pages in the order of the index keys. The database manager does not maintain any order of the data when compared to the order of the corresponding keys of a non-clustered index.
Bidirectional indexes
Bidirectional indexes allow scans in both the forward and reverse directions.
The ALLOW REVERSE SCANS clause of the CREATE INDEX statement enables both forward and reverse index scans. That is, in the order that is defined at index creation time and in the opposite, or reverse order. With this option, you can:
- facilitate MIN and MAX functions.
- fetch previous keys.
- eliminate the need for the database manager to create a temporary table for the reverse scan.
- eliminate redundant reverse order indexes.